
1.1 Introduction
DBMS came to rescue us from the pitfalls that were highlighted in the previous chapter. All the cons of having data in the file systems were solved by having them in a DBMS – the database management systems.
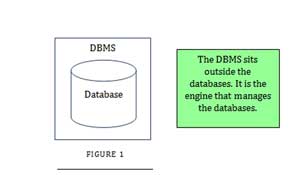
1.2 What is a DBMS
DBMS is a software that manages the databases. All your data is stored in the database. So instead of talking directly to the database, you talk to the DBMS. If everyone talks directly to the database, it becomes messy. Everybody is putting his or her hand into the honey pot. Instead of that, the DBMS forms a queue, asks people to wait their turn and serves them portion of honey. Honey in our case would be the data they have been waiting for. Once they manipulate the ‘honey’ i.e. the data the DBMS puts it back into the database.
 Another way to think of the DBMS is to compare it to a librarian. Some of the past journals have been archived. If you allow everyone to go into the archive room then it becomes messy. So if you want something then you ask the librarian. She asks you to wait, goes into the archive room and gives what you asked for. If there are many people then she works on a ‘first come first served basis’. If two people ask for the same material then she asks the second person to wait. She kind of puts a ‘lock’ on the material. It is not available for others.
Another way to think of the DBMS is to compare it to a librarian. Some of the past journals have been archived. If you allow everyone to go into the archive room then it becomes messy. So if you want something then you ask the librarian. She asks you to wait, goes into the archive room and gives what you asked for. If there are many people then she works on a ‘first come first served basis’. If two people ask for the same material then she asks the second person to wait. She kind of puts a ‘lock’ on the material. It is not available for others.
So this – in a nutshell - is what the DBMS is all about. It manages the Databases. There is only one problem. The librarian understands only one language. That language is SQL - The standard or structured query language.
I have explained some advanced concepts by way of this simple example. ‘Locking’ is one such concept. If one person has taken a particular piece of data then the DBMS puts a lock on it. Until that person finishes his work on that piece of data – it is not available for others to see. Because if they see – they might see a half-baked cookie. This is one job of the DBMS.
The only language this librarian understands is SQL –standard (structured) query language. A database query language, which is covered in a separate tutorial.
Characteristics of a DBMS
Time has come to specify formally the characteristics of a DBMS that we have been discussing:
Transaction/ Two stage commit process
The data manipulation in a database is carried out in the form of transactions. The concept of Transactions help us to understand completeness. Just like the accounting transactions – where you debit one account and credit another account for a single transaction for completeness. There is also a Two stage commit process where each transaction is first written to the database and then ‘committed’ to it permanently. IF you are unhappy with the transaction you can ‘rollback’ the transaction. .i.e. undo the change you did before it is written permanently to the database. More on this later. (You must also understand that some of the modern DBMS systems these concepts are very blurred. For e.g. Oracle’s concept of Flashback queries.)
Consistency
Because databases uses the concept of transaction the data in the database is consistent. For example if you transfer 500packets of milk powder from one warehouse in Boston to another in Lowell you need to reduce 500packets from Boston warehouse and increase 500 packets to the Lowell warehouse. DBMS makes sure that both of these has to be done consistently. For example what happens if there is a power failure after you reduce the Boston stock before you add to the Lowell stock? The concept of transactions and two stage commit allows us to be consistent. You only commit the transaction once it is complete. i.e. after you reduce and add to the relevant warehouses – only then you commie – you make the changes permanent to the database. So if there is a power failure after you reduce the stock and before you increase the other – since it is not committed i.e. not made permanent – the whole transaction will get reversed. You can run reduce and add later when the power comes.
Less Redundancy
Data repetition is minimalized greatly. A Process called normalization helps to reduce the redundancy.
Multi User Capability
A DBMS must be able to manage multiple users at the same time. And treat each user as if he was the only user on this earth. How I wish all my suppliers treat me like that! However a user might be notified of another user if both are working on the same resource (for example in case of a deadlock – more on this later!)
ACID
A customary term. Atomic. Consistent. Isolation. Durability.
Atomic - transactions are atomic. They are like some eccentric men. They work on all or nothing basis. All parts of a transaction get committed or nothing gets committed. As I explained earlier in the consistency section.
Consistency – already explained. The customary definition is that transactions transform the database from one correct state to another – it may not have the intermediate states.
Isolation - there may be many users running many transactions all at the same time – concurrent transactions . But each transaction is isolated from each other until it is fully committed.
Durability – once the changes are committed it is permanently held in the database until is changed by the user.
Security
DBMS provides security at different and all levels to make sure that there is no authorized access. Security can be enforced at the Database level, Table Level, Row Level and Colum Level. It is like having a security guard at the main gate, then at the door then at the hall and finally near the dining table!
Meta Data
Met a Data is the data about data. Another customary definition. Since the amount of data is vast – the DBMS should have some data for its own use. This data would help the DBMS to see how much data there exists in a particular table. How much of the allocated storage has actually been used. As you see – this kind of data will enable DBMS to manage the its databases effectively.
As time went on the divide between man and machine narrowed. Machines wanted to do what men were supposed to do, and men were willing to do some things that the machines were supposed to do.
So the some of the Meta data which was originally meant for the DBMS was shared for the humans. So the answer to the famous interview question ‘how would you find out how many rows are there in the table?’ is not I will query the table (if you know sql – select count(*) from table) but rather I will query the meta data – the data which contain data about data.
What is database?
A Database is a collection of related data. It is organized for easy retrieval and optimal storage. A database is typically managed by a DBMS. And a DBMS can manage many databases. A database is created for a system.
Let’s understand this through an example. You can create a database for a customer relationship management system (CRM). So a database typically is dedicated for one system. While a database technically will allow you to keep data about other things also it is not a recommended practice. In the CRM example you can keep data about your stock control system in the same database. However it becomes messy.
So now even if we limit the amount and type of data that we are going to keep by saying that one database should typically have data about one system we still are faced with a problem. There is too much data. In the CRM system we need to keep customer data. The number of complaints the customers make. The number of times we contact the customers. And if there is anything to be done – who is supposed to do that and how to keep track of them.
If we want to keep all this data in an organized way so that storing is efficient and retrieval is easy then we need to find a way of breaking this CRM system further down. So we have to keep all this data in a meaningful way in some smaller structures.
Tables, Records and Fields
To solve this problem People came with an indigenous concept called the tables or entities. Each table would keep data about a particular entity. This was a Data Driven Approach where we look at the world as a set of entities. A customer is an entity. A Vehicle is an entity. A Mobile is an entity.
Each of these entities has attributes. A customer has a name, has an age, has an address. Each of those attributes has a value. Typically called the attribute-value pair – this is no rocket science!
See the diagram below for illustration.
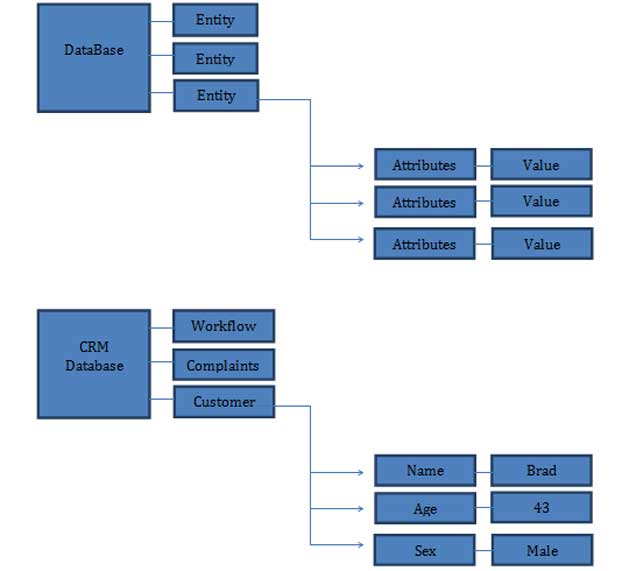
I have only shown the attributes of the customer each of entities also have attributes.
So each entity is called a Table. So data was kept in the form of two dimensional tables. And each row in a table is called a record. Each column is called the field. Any guesses as to why we call it the two dimensional tables?!
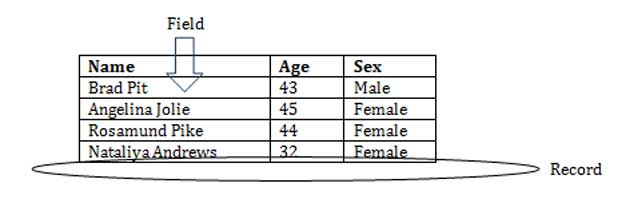
Name | Age | Sex |
Brad Pit | 43 | Male |
Angelina Jolie | 45 | Female |
Rosamund Pike | 44 | Female |
Nataliya Andrews | 32 | Female |
While we will not be going into the details this model is based on the mathematical set theory. So is the database language SQL.
Entities and Tables
While an entity is a conceptual thing a table is a database or physical thing. Physical not in the sense that you can touch and feel! For that matter you can’t touch and feel anything in the computer except the hardware! But physical in the sense you can issue a SQL command to create them and also in the sense that it occupies space in the hard disk.
You can read data from a table, you write data to a table you can update a table and delete data from the table. Entities are simply concepts which map to tables.
If you were a thinking like me you would be confused about one important aspect – Isn’t the tables the same thing as files – the flat files? Well, NO! For one thing tables are stored in a database which in turn is managed by the DBMS. For another thing the table is simply our perception. If you scan the hard disk you will not find any two dimensional structures called tables. But files will be visible in the hard disk. In one way tables are like the longitudes and latitudes. We know that they don’t really exist. But if say 38.8951° N, 77.0367° W you know that it is Washington DC. IT is not that the longitudes and latitudes are written over Washington DC. But they help!
We will be looking at Entities when we look at the Logical and Physical Design of databases in another chapter.
Logical and Physical Models
That brings us to an important distinction – between a data model and its implementation. Tables, Attributes etc. form the basis of a data model. Or the Logical Model. Then the data is kept on the hard disk as files, indexes etc. this defines the Implementation. Or the Physical Model. The users should be aware of the Logical data Model, whereas they ideally should not be worried about the physical model. While most of the tasks related to the physical model are handled by the DBMS itself some of the tasks can be carried out by the DBA – the Database Administrator.
So there is actually data independence. The physical and logical layers are independent of each other. This allows us to copy the database from one computer to another or to change underlying the hard disk or storage mechanism.