
1.1 What is Hadoop
Hadoop is a framework that is Scalable, Fault Tolerant and Highly Available and offers Distributed computing over large data sets.
Let us try to understand each term used in the definition.
Scalable Scalable means the limit of expansion, Hadoop is highly scalable in a way you can extend it from one server to many machines. Fault Tolerant Hadoop has high degree of fault tolerance. Jobs run on large clusters with many nodes or network components. These nodes may experience high rates of failures. In that case Hadoop manges the jobs to successful completion. Master Node or Name Node: If master node goes down, Hadoop uses backup master node to support the operations. Slave Node or Data Node: Data is duplicated among various data nodes, so even if any of the data nodes fails, the data would still be preserved. Highly Available Hadoop is highly available in a way that data would always be available for processing; absolutely no loss of data. Same data is replicated in more than one data node among all the data nodes. The default limit for replication is 3 means same data is present in 3 different data nodes. Distributed Computing In Hadoop framework computation takes place in cluster of commodity computers using some programming logic. Hadoop divides a large dataset among various data nodes and executes small data sets in each individual data node separately but in parallel and in real time. This feature boosts up the speed of operation. |
Birth of Hadoop
In 2003 Google released one white paper over internet in which they explained the internal data processing of their system. It explained very much about how they are able to perform immense processing of data. This architecture inspired the makers of Hadoop.
1.2 Why we need Hadoop
Please read the following before we try to find out the need of Hadoop
“In today’s modern computerized era we are adding in every 2 days the same amount of data that mankind has ever produced from the inception till early 21st century. “
This clearly explains how with such an accelerated rate we are generating data. Question comes from where all these enormous chunk of data come from and the answer is here:
· Thousands of servers generating multiple lines of log
· Searches made over search engine
· Posted data over social networking sites
· User filling up inquiry forms
· Increasing size of data warehousing
· The growing demand of mining and analytics necessitates increasing size of data
The last bullet point is very interesting as currently in today’s era the business competition is very high and it demands lot of data mining and data analytics. Data mining and data analytics demand companies to have as much data as they can afford to store, since bigger data would yield better results. This forced them not to delete or purge data but to store as much as they can.
Due to the increasing size of data, we need good programs/algorithms to process it effectively and we have to make sure that it is processed without loss of any data. If someone is asked to propose a solution to this problem then he/she would probably suggest increasing the server capacity to store and process this growing large amount of data. But is it really a practical solution? Think over this, for how long you can afford to do this? Would that be cost effective? And the biggest question is, would it be a feasible solution on a particular day in future? Definitely this cannot be a practical approach.
This forced people to think differently and they came up with the idea of Hadoop. Later on, in this tutorial we will understand how Hadoop addresses the entire problem with its powerful framework.
We have a need of something that should be like ‘Write Once & Read Many Times’. Hadoop works exactly on this model.
1.3 Understand Big Data
Two types of data exist:
Structured Data
This is our very much normal data that traditional RDBMS system possesses. This is all well-defined row column based data, obeying codd’s rules for RDBMS.
Unstructured Data
Includes following –
- Log generated from server
- Images
- Data posted over social networking site
- String search over search engine
- Data contained in pdf file
The data mentioned in the second category is known as the Big Data. It is known as Big Data since this kind of data carries a larger size. The Biggest challenge is to store them in tabular form and process it. Hadoop supports Big Data processing very well.
We can process structured data with traditional programming approach, but cannot do the same with unstructured data. However Hadoop can process structured and unstructured data in a very effective manner. Hadoop’s underline architecture support unstructured data.
Hadoop works very well when you have large data sets and not when you have small datasets since a lot of Hadoop’s resources would go waste in maintaining metadata information of lot of smaller datasets. We will understand these things completely when we later read further chapters in this tutorial.

1.4 HDFS And Map Reduce
HDFS
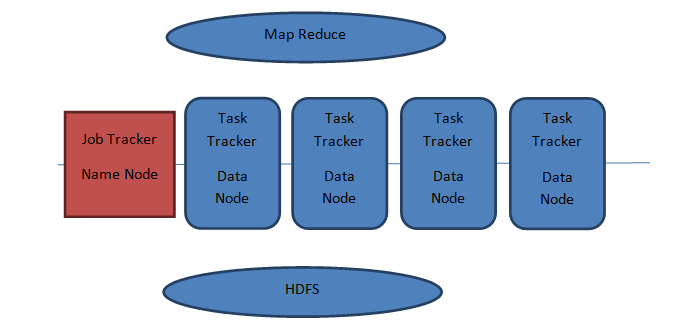
There is an underline file system of Hadoop known as HDFS. HDFS stands for “Hadoop Distributed File System”. Hadoop has a distributed computing power which enables not to rely on single server for execution but to perform execution over a series of many small commodity computers in a cluster environment.
HDFS is made up of master/slave relationship where it has one master known as ‘Name Node’ and several slaves known as ‘Data Node’. Master node keeps a track of files assigned to data node. Data Node takes part in processing the file, read and writes.
Map Reduce
One more component of Hadoop framework is ‘Map Reduce’ which is a programming model framework built up of master/slave relationship where it has one master known as ‘Job Tracker’ and several slaves known as ‘Task Tracker’ that runs per data node machine. Job Tracker is responsible for job scheduling and monitoring on each data node. The data node performs execution as instructed by the Job Tracker.
Let us move towards the next chapter and we will understand various components involved in Hadoop’s architecture and how each component is connected to one another. This will help us visualize the big picture of Hadoop that involves HDFS, Map Reduce and other components to achieve the final goal of powerful distributed computing that is fully scalable, fault tolerant and highly available.