6.1 What is Hive
Hive is SQL (Structured Query Language) type of programming language that runs on the platform of Hadoop. It was created to manage, pull, process large volume of data that Facebook produced.
We assume that you would already been familiar with the classical RDBMS (Relational Database Management System) and its underlying architecture along with the SQL structure and semantics. As Hive is part of Hadoop cluster so when a Hive query is submitted it gets converted into a sequence of Map Reduce jobs.
6.2 Hive Installation and Configuration
Installation of Hive is as same as that of Hadoop and Pig. Remember that JAVA 6 is very mandatory requirement for the Hive installation. Begin the installation first by downloading the Hive software from the apache web link. Then run the command as:
% tar xzf hive-x.y.z.tar.gz
Set the environment variable HIVE_HOME to point to installation directory at $HOME/.bashrc:
$ export HIVE_HOME=/hadoop/hive-x.y.z
Finally, add $HIVE_HOME/bin to your PATH:
$ export <<path>>=$HIVE_HOME/bin:$<<path>>
To begin Hive
#bash
#hive
6.3 Writing Simple to Complex Hive Queries
The Hive Shell
Hive's query language is known as the HiveQL. We write HiveQL in a shell that is known as the Hive Shell, it is the primary way to interact with Hive. AS we already mentioned that Hive is quite similar to SQL, and we would like to mention that Hive is heavily influenced by
MySQL. It would definitely be an added advantage if you would already know the MySQL. We can enter into Hive Shell by issuing command as:
%hive
hive>
As we are starting it for the first time so we can check whether it is working by listing its tables. There should be no table listed. While running the Hive query it should be terminated with a semicolon to tell Hive to execute it
hive> SHOW TABLES;
HiveQL is not case sensitive, definitely except for string comparisons. So even if we write query as hive>show tables;
It would work fine. During writing a Hive query the Tab key will automatically complete the Hive keywords and functions. Remember that when you are using the Hive for the first time in a fresh installed machine, the command takes a few seconds to run since creates the
metastore database on your machine. This database stores Hive's files in a directory called
metastore_db, that is very much relative to the location from which you ran the hive command. In order to run the In order to run the Hive shell in non interactive mode following command can be issued -
% hive -f script.q
For short scripts we can use the -e option to specify the commands inline, and in this scenario the final semicolon is not required.
% hive -e 'SELECT * FROM dummy'
In both interactive and non interactive mode Hive prints information to standard error, such as the time taken to run a query during the course of operation. These messages using the -S option at launch time, which has the effect of showing only the output result for queries:
% hive -S -e 'SELECT * FROM dummy'
Suppose we have some data in a file so to make all those data as part of Hive table following query can be used:
% hive -e "CREATE TABLE dummy (value STRING); \
LOAD DATA LOCAL INPATH '/tmp/dummy.txt' \
OVERWRITE INTO TABLE dummy"
Suppose we want to read a file that has columnA as string, columnB as integer and columnC as integer so we can issue a hive query to read this tab delimited file as:
CREATE TABLE records (columnA STRING, columnB INT, columnC INT)
ROW FORMAT DELIMITED FIELDS TERMINATED BY '\t';
We can run standard queries in almost the same way:
Now that the data is in Hive, we can run a query against it:
hive> SELECT columnA, MAX(columnB)
> FROM dummy
> WHERE columnC != 9999
> GROUP BY columnA;
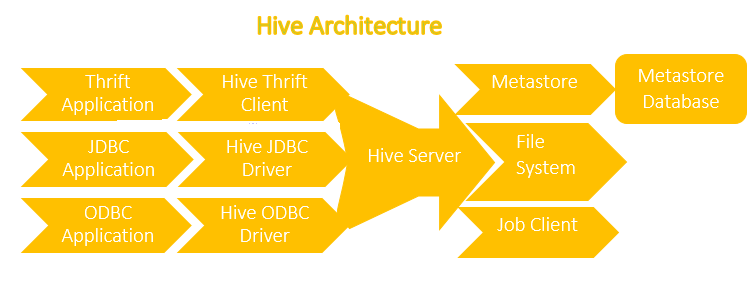
Thrift Client
The Hive Thrift Client is used to run Hive commands from programming languages such as
C++, Java, Python, PHP and Ruby.
JDBC driver
Hive provides JDBC driver that is defined in the class
org.apache.hadoop.hive.jdbc.HiveDriver. When you configured it, Then a Java application will connect to a Hiveserver which is running in a different process. Here one thing to note down that JDBC driver uses Thrift to communicate with the Hive server.
ODBC driver
Like other tools and technologies Hive also used ODBC driver that allow the application that support the ODBC protocol to establish a communication with Hive. Like the JDBC driver, the ODBC driver also uses Thrift to communicatewith the Hive server.
The Metastore
The main (very important component) central repository of Hive metadata is known as the metastore. Basically metastore is split into two components –
- A Service
- The backing store for the data
The metastore service runs in the same JVM as thatof the Hive service and it contains an embedded Derby databaseinstance which is backed by the local disk. This is known as the embedded metastore configuration. Here one thing to note is that only one embedded Derby database can access the database files on disk at any one time that meansthere can only be one Hive session open at a time that shares the samemetastore.
A high-level comparison of SQL to HiveQL
Utility | SQL | HiveQL |
Indexes | Supported | Supported |
Updates | Update, Insert, Delete | Insert |
Transactions | Supported | Supported at Table and Partition level |
Functions | Large variety of Built In function supported | Few Built In function supported |
Multitable Inserts | Not Supported | Supported |
Joins | Supported | Supported |
Views | Materialized and Non Materialized | Only Non Materialized |
Sub queries | Supported in any clause | Supported only in from clause |
Hive Architecture