
11.1 Ambari
Ambari is an operational framework that is used to manage and monitor Apache Hadoop cluster. Ambari has collection of operator tools and set of APIs that simplifies the way to operate on Hadoop cluster and reduce the complexity. Managing a Hadoop cluster is not an easy task since it involves a lot of component altogether. This becomes more of a big issue when the size of cluster is large, sometimes hundreds or thousands of hosts involved. Ambari actually provides a very single control point for view, update and manage Hadoop service life cycles.
Ambari provides lot of features and functionality especially for the administrator to use and work with. Here is a list of those:
Establishment Hadoop Cluster
Ambari simplifies the operation of deployment and maintenance of hosts in Hadoop cluster irrespective of the size of Hadoop cluster. Ambari has a very good web interface that allows you to perform –
- Easy provisioning
- Effective configuring
- Testing all the Hadoop services and core components
Other than this Ambari provides a very powerful Ambari Blueprints API to automate cluster installations where you do not need to user intervention.
Manage Hadoop cluster
As we already specified that Ambari provides set of tools to simplify the cluster management process. Its web interface allows us to control the lifecycle of Hadoop component and services. You can easily modify configurations and manage the growth of your cluster. Ambari manages Hadoop cluster effectively.
Monitor Hadoop cluster
You can monitor the health of your Hadoop cluster comfortably and gain good instant insight of it. In web interface Hadoop services can be watched and visualize cluster performance.
Integrate Hadoop with the Enterprise
In order to merge with other establish operation processes, Ambari provides API that enables integration with existing tools. The list of these includes:
- Microsoft System Center
- Teradata Viewpoint
- Wizard driven installation
Ambari provide a wizard driven installation of Hadoop across any number of hosts.
11.2 Avro
Avro is developed as Apache’s Hadoop project which is a remote procedure call and data serialization framework system. Avro defines data types and protocols using JSON. Avro serializes data in a compact binary format.Avro specifies a format in the form of object container format for the sequences of objects. Avro stores the schema of datafile in metadata section. This makes the file self-describing.
Avro datafile:
- Supports compression
- Are able to split
Both these features are very crucial for a MapReduce data input format. Avro defines some data types that can be used to buildapplication-specific data structures.
Data Type | Schema | Remarks |
null | null | absence of a value |
boolean | boolean | binary value |
Int | int | 32 bit signed integer |
Long | long | 64 bit signed integer |
Float | float | 32 bit single precision |
double | double | 64 bit double precision |
Bytes | bytes | 8 bit unsigned bytes sequence |
String | string | Unicode character’s sequence |
Avro also defines the complex types:
Type | Remarks |
Array | It is an ordered collection of objects. Note that all the objects in a particular Array should have the same schema |
Map | It is an unordered collection of key-value pairs. Keys should always be type of string and values may be of any type. Note that withina particular map, all values should have the same schema |
record | It is a collection of named fields of any type |
enum | It is a set of named values |
Fixed | A fixed number of 8-bit unsigned bytes |
Union | A union of schemas. In union each element in the array is a schema |
Avro’s object container file format is used to store sequences of Avro objects. Avro’s datafile is verysimilar to Hadoop’s sequence file in design. The main difference between these two is that the Avro datafile are designed portable across languages. So, you can write a file in one language and read it in another language. A datafile has components:
- A header that contains metadata information
- Avro schema
- Syncmarker (All the Blocks are separated by this)
- Series of blocks containing the serializedAvro objects
11.3 Spark
Apache Spark is data analytics cluster computing framework. It is a very fast lightning cluster computing system. It has the ability to work on top of a Hadoop cluster. Sometimes it performs better than MapReduce in more efficient way in several operations. It actually works more in RAM as compare to MapReduce. MapReduce is of batch oriented in nature, hence for iterative processing in the case of machine learning and interactive analysis, Hadoop’s MapReduce doesn't meet the requirement. Definitely we cannot say that Spark is a complete replacement of Hadoop as writing Hadoop is much mature when compared to Spark. Cloudera has already started including Spark in CDH and over the period of time more and more vendors would be including it in their Big Data distribution. In future we may find MapReduce and Spark going and working in parallel. With Hadoop 2 also known as aka YARN, MapReduce and other models including Spark can be run on a single cluster. So what is happening that Hadoop is not going anywhere and Spark is eliminating lot of Hadoop's overheads, remember that Spark is an extension of Hadoop. If you use Hadoop in processing logs then Spark probably won't help you out. Instead, if you have very complex problem then Spark would definitely help a lot. In addition to this you may use Spark's Scala interface for online computations.
Spark:
- Is part of Hadoop open source community
- Built on top of the Hadoop Distributed File System (HDFS)
- Not bound to the two level MapReduce model
- Performs up to 100 times faster than Hadoop MapReduce for certain applications
- Provides primitives for in-memory so that to do cluster computing
- Well suited for machine learning algorithms
- Has distributed memory based architecture
- Is used at a wide range of organizations in order to process large datasets
Here are the following features of Spark:
- It has support of APIS from Java, Scala, and Python and you can write applications quickly in these languages
- Supports caching for datasets in-memory processing to perform data analysis. It works like you first selects a data set then cache it followed by query it repeatedly
- Provides a very interactive command line interface in language like Scala or Python to perform low latency data exploration
- It has a higher level library for Spark stream processing, machine learning and graph processing. Spark powers a range of high level tools including Spark SQL, MLlib for the machine learning, GraphX, and Spark Streaming. We can easily combine all these frameworks flawlessly in the same application
- It can easily be run on Hadoop 2's YARN cluster manager. Spark has the ability to read any existing Hadoop data. Spark can be run without any installation needed if you have a Hadoop 2 cluster available with you. Spark reads easily from HDFS, HBase, Cassandra and any Hadoop data source
11.4 Chukwa
Chukwa is a built on top of the Hadoop Distributed File System and MapReduce framework. Chukwa inherits Hadoop’s scalability and robustness.Chukwa, an open source data collection system, a part of Apache incubation, is basically used for monitoring large distributed systems. Chukwa has a flexible and powerful collection of tools in order to display, monitor and analyze results and make the best use of the collected data. It supports legacy system as well as data source.
Chukwa:
- Is very reliable system in the sense, it records how much data from each source has written successfully, resumes at that point after crash and fix duplicates in the storage layer. We can tolerate multiple concurrent failures without losing our data
- Is highly practical in use as it is being used at several sites
- Has high scalability capability since it is built on top of Hadoop for processing and storage
- On its own it doesn’t do analysis or indexing
- At the back end side, has a concept of parsed records with complex schemas.
- Is neither storage nor processing. It is actually a collection system and not responsible for storage, it uses HDFS. Is also not responsible for processing, it uses MapReduce. The idea is that it is responsible for facilitating storage and processing
- Represents a design structure in between two existing stream of systems. One is the log collection framework and other is a network management system. Chukwa combines the plenty of data display tools of existing network management system with the high throughput and robustness
- Is optimized with highly optimized design and precise structure for storage along with batch processing. Now a days enormous data gets collected every day, processing the stored data becomes a key tailback
- Demonstrates a high performance distributed monitoring system, it can easily be built upon existing distributed data collection framework. HDFS supports petabytes of stored data with hundreds of megabytes per second of write throughput, this is more than sufficient for even very demanding monitoring applications. Along with this, MapReduce provides a suitable framework for organizing and analyzing high data volumes
Here is the architecture:
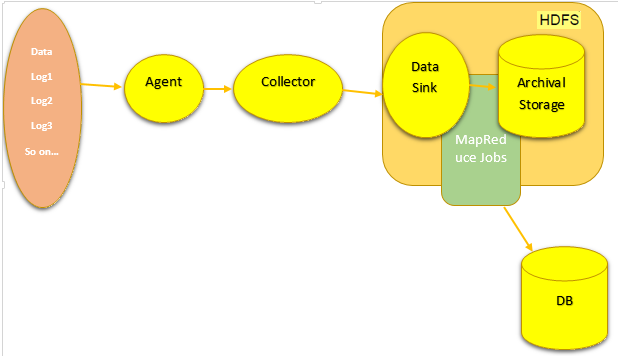

11.5 Mahout
The Apache Mahout is a scalable machine learning libraryimplemented on top of Hadoopand uses the MapReduce paradigm for faster parallel processing. Machine learning –
![]() Belongs to artificial intelligence
Belongs to artificial intelligence
![]() Focuses on make it possible for machines to learn without being explicitly programmed
Focuses on make it possible for machines to learn without being explicitly programmed
![]() Is normally used to improve future performance based on previous consequences
Is normally used to improve future performance based on previous consequences
Mahout provides enables to automatically find meaningful patterns in big data sets. The Apache Mahout project aims to turn big data into enormous information in a much faster and easier way. Mahout is distributed under the Apache software license. Mahout provides an application of various machine learning algorithms, provide in both modes –
- Local mode
- Distributed mode
Distributed mode is being used for Hadoop. Each and every algorithm written in Mahout can be invoked using the Mahout command line.
As of now the Mahout supports mainly three belongings:
- Recommendation – In recommendation, mining takes user’s behavior in order to find items users might like
- Clustering – In clustering, receives text documents and assemble them into groups of related documents
- Classification – In classification, learns from existing categorized documents (a specific category look like) and on the basis of this assigns unlabeled documents to the correct category
11.6 Cassandra
Cassandra is NOSQL distributed database. It is a high available system with no point of failure. Cassandra is open source, distributed storage, it relies on commodity hardware and scales out on cheap. Its architecture model is peer to peer. It can be installed on Linux, Windows or MacOS. It supports unstructured data and has a flexible schema. In Cassandra referential integrity is not enforced.
Cassandra is good for:
- Perform tracking
- Analysis on the data of time series
- Sensor data analysis
- Risk analysis
- Prediction of failure (which servers are under heavy load and about to fail)
11.7 DataWarehousing
A DataWarehouse system is mainly used for keeping historical data. We create a central repository of data where data comes from one or various data sources. The type of data that DataWarehouse store is current as well as historical data. DataWarehouse data is been used in lot of different types of reporting and data analysis including the analytics.
Don’t think Hadoop will replace DataWarehouse system because DataWarehouse has its own feature and Hadoop offers its own feature. DataWarehouse stores the massive amount of data specially the historical data and would assure of your records are safe. However on the other hand Hadoop has a capability of doing massive data processing with its immense power stored in distributed cluster of commodity computers that includes powerful MapReduce paradigm.
11.8 Mining
Data mining is a process of extracting more and more information from the available information. We use various algorithm in accompanying data mining. If the data size is huge then there may be an issue in data processing. We can use Hadoop for faster data processing.