
This chapter will introduce you to the first step of learning C language. As we have to learn alphabets to learn English language, similarly we will learn the alphabets to learn the C language.
3.1 Character Set (Alphabets of C language)
The characters which are used to write C programs are called Character Set or alphabets. Every programming language has its own character set. This set of characters form the lexical elements. The characters used in C language are generally categorized under following categories:
- Letters
- Digits
- Symbols
- White spaces
Letters: Upper case letters from 'A' to 'Z' and lower case letters from 'a' to 'z'.
Digits: This category include the digits from 0 to 9.
White spaces: Characters such as space, tab (\t), new line (\n), carriage return (\r), etc are included in C language and they are known as White spaces.
Symbols: This category include special symbols like :
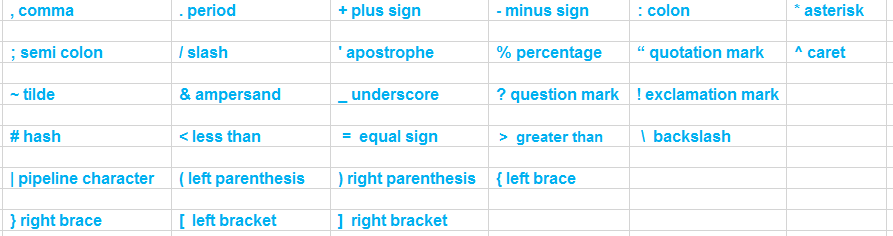
Character set of C
3.2 C Tokens
Alphabets are combined together to form meaningful words called tokens. We can define token as the smallest unit of program. Characters are grouped together to form meaningful words and these meaningful words are termed as Tokens.
Tokens are broadly categorized into following categories and they are as follows:
- Keywords
- Identifiers
- Constants
- Operators
- Special symbols
3.3 Keywords and Identifiers
Those words which have predefined meaning in C language are called keywords. In fact, every word in a C program is an identifier or keyword. All keywords are reserved words. They are sequence of characters which have one or more fixed meaning. These meanings cannot change in any circumstance. Keywords must be written in lowercase. C is a case sensitive language so uppercase and lowercase letters are significantly different. The keywords cannot be used as variable names. It is because it means that we are trying to assign a new meaning to keyword which is not permissible. There are only 32 keywords available in C. Following keywords are supported by ANSI C.
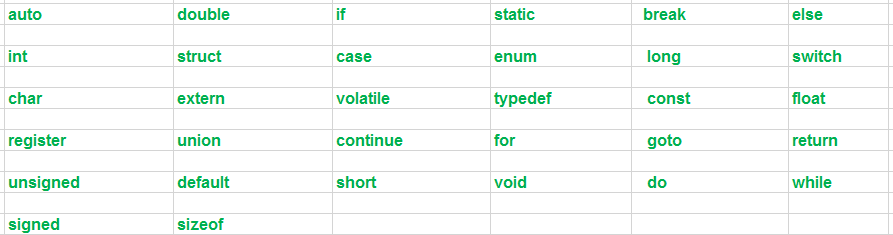
Figure C Keywords
Identifiers are the program elements like variables, arrays and functions. We can also say identifiers are sequences of alphabets and digits. There are certain rules which need to be followed while constructing identifiers and they are as follows:
- The first character in identifier should be a letter or “_” and can be followed by any number of letters or digits or underscore.
- Any other symbols except letters, digits and “_” are not allowed.
- Length of an identifier can be up to a maximum of 32 characters
- It is not recommended to use underscore as identifier although it is a valid identifier
3.4 Data types
Data types are broadly categorized into two categories and they are as follows:
- Primitive Data types
- Secondary Data types
3.4.1 Primitive/Basic/Simple Data types
Data type and variable are two different things. When we execute a program a variable can have different types of values in memory. The type of value the variable will hold in memory is represented by data type. Primitive data type is also called Basic data type or Simple data type or Fundamental data type. We have the following types of primitive data types:
- int
- char
- float
- double
- void
int: This keyword is used to define integer numbers. They are associated with variables to store signed integer values in memory locations. We can store positive and negative numbers in memory. Usually we represent unsigned numbers by the keyword unsigned. For instance, unsigned int will represent positive numbers.
char: This keyword is used to define single character. It can also define sequence of characters called string. Each character stored in memory is associated with a unique value called ASCII value. ASCII stands for American Standard Code For Information Interchange. The char variables can be used to store a character or string in memory location.
void: This represents empty data type. We use this keyword in conjunction with function. This function indicates that it is not going to return any value. This data type is only associated with pointer variables.
float: This keyword is used to represent floating point numbers. Floating point numbers are also known as real numbers. They are used to store floating point numbers in memory locations. Here both positive and negative floating point numbers can be stored using this data type.
double: This keyword is used to large floating point numbers with high precision. These variables store large floating point numbers in memory locations. Both positive and negative large floating point numbers are stored in memory location using same keyword.
3.4.2 User defined data types
User defined data types are renamed or defined by programmer. They are derived from the primitive data types. User defined data types can be used to declare variables also. For example,
typedef d_type identifier;
where,
typedef is keyword
d_type is the primitive or another user defined or derived data type
identifier is the name given to the d_type
We are concluding this chapter. Next chapter will introduce variables and constants.